This note summarizes the system design and technical insights from building a banking customer service assistant powered by retrieval-augmented generation (RAG) and tool-calling.
1. Project Context
In the banking industry, customer service teams often handle large volumes of repetitive queries, especially around account management, credit cards, and loans. While traditional FAQ systems rely on keyword matching or rule-based responses, they tend to:
Misunderstand intent
Provide irrelevant answers
Lack integration with backend systems
To solve these issues, we designed a hybrid system combining semantic retrieval and LLM-based reranking, with support for API-triggering capabilities when needed.
2. System Architecture
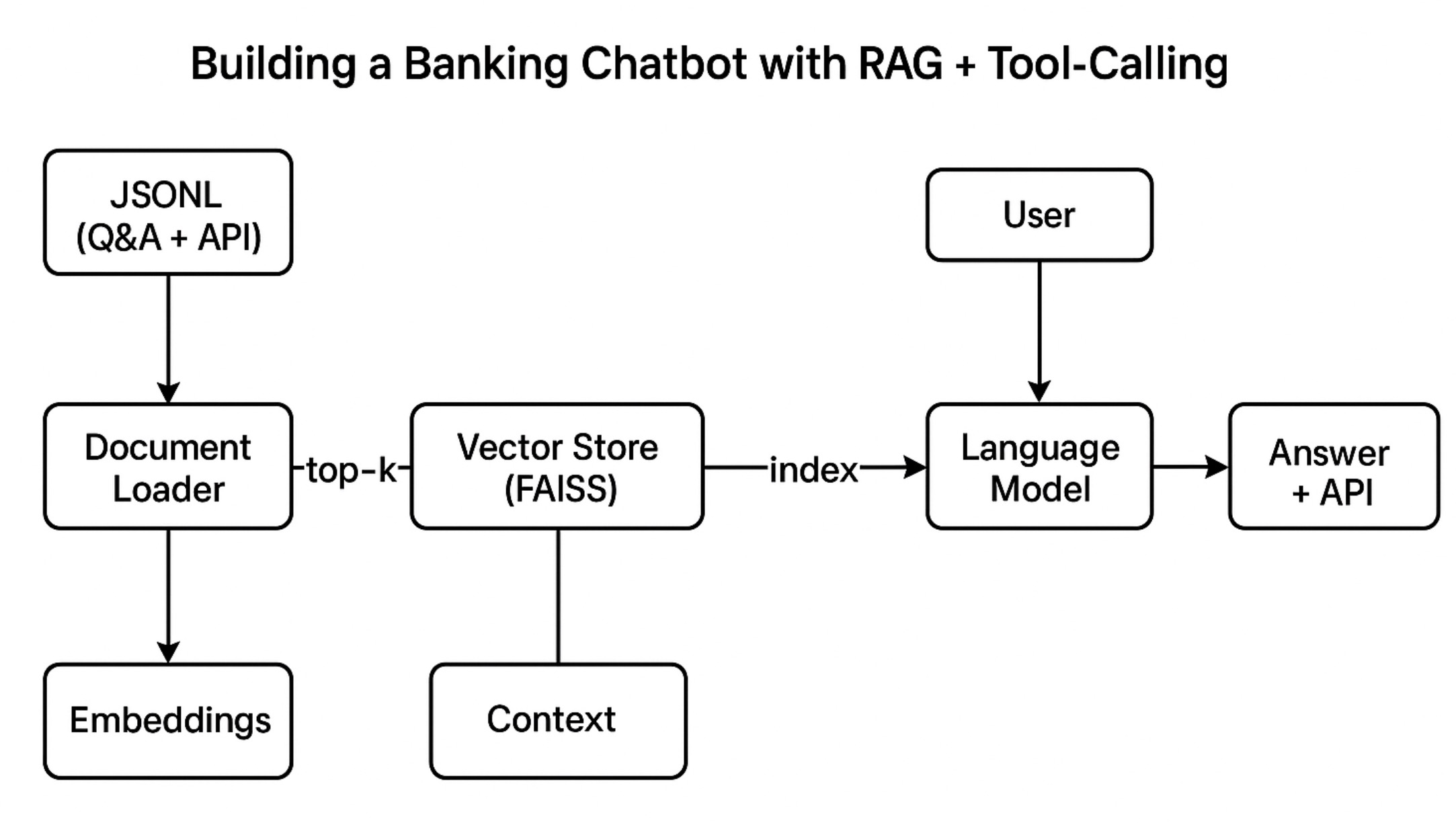
3. Component Breakdown
🧾 a. FAQ + API-Linked Knowledge Base
The knowledge base is stored in JSONL format, where each item includes:
{
"question": "How do I apply for a credit card?",
"answer": "You can apply via mobile banking, our website, or at any branch...",
"api": "/apply-credit-card"
}The presence of the api field allows downstream processes to determine whether an automated action can be taken.
🧠 b. Embedding & Vector Search with FAISS
Documents are chunked and embedded using the BAAI/bge-base-zh model.
FAISS is used to build a high-performance local vector index.
For any incoming user query, the system retrieves Top-K semantically similar Q&A items.
🎯 c. Prompt-Based Reranking (Index Selector)
To avoid hallucinated responses and keep answers grounded:
Retrieved Q&A pairs are labeled numerically (0, 1, 2, …).
A structured prompt is passed to the LLM asking it to return only the number of the best-matching item.
This pattern turns the language model into a semantic ranker, not a generator—ideal for enterprise settings where control and consistency are critical.
🤖 d. Language Model Inference
The system uses an OpenAI-compatible model (e.g. Qwen) to rerank the results and identify the best response based on intent and similarity.
Fallback logic is implemented: if no suitable match is found, a default response such as
“Sorry, I’m unable to determine the answer at the moment.”
is returned.
🔁 e. Structured Output for API Integration
The final response is returned in a structured JSON format:
{
"answer": "...",
"api": "/apply-credit-card",
"related_questions": ["How to apply for a debit card?", "How to apply for a credit loan?"]
}The frontend or backend can then:
Display the answer directly
Offer related queries to the user
Automatically trigger the API if the field is present and authorized
4. Key Learnings
✅ What Worked Well
Reduced hallucination risk via controlled prompt selection
Clean separation between NLU and execution layers
Ready-to-integrate JSON structure for downstream systems
Strong support for Chinese Q&A scenarios using bge embeddings
🔄 Future Improvements
Multi-turn context tracking for dialogue continuity
Graph-based reasoning (e.g., GraphRAG) for complex Q&A
Native function-calling integration for auto-execution
5. Final Thoughts
Working on this project gave me firsthand experience designing a scalable, controllable AI assistant architecture for enterprise use. It deepened my understanding of RAG pipelines, prompt engineering, and how to connect natural language understanding with real-world business logic.
In the future, I aim to explore more advanced agent-based architectures that combine memory, planning, and tool execution into a unified AI assistant capable of real workflow automation.